source: https://ai.gopubby.com/agentic-rag-with-llama-index-function-tool-calling-02-f2bd04558f84
In the last article, we delved into the basics of Agentic RAG and successfully built a straightforward Agentic RAG application. We explored foundational concepts and practical steps to get our initial application up and running using the Router Query Engine. In this follow-up article, we’ll elevate our understanding by incorporating a powerful feature: function calling, also known as tool calling. This enhancement will significantly expand the capabilities of our RAG agents. So, let’s embark on this next phase of our journey and explore how to integrate function calling into our RAG applications.
在上一篇文章中,我们深入探讨了 Agentic RAG 的基础知识,并成功构建了一个简单的 Agentic RAG 应用程序。我们探讨了使用路由器查询引擎启动和运行初始应用程序的基本概念和实际步骤。在这篇后续文章中,我们将结合一个强大的功能来加深理解:函数调用,也称为工具调用。这一增强功能将大大扩展 RAG 代理的功能。因此,让我们开始下一阶段的旅程,探索如何将函数调用集成到 RAG 应用程序中。

Image By Code With Prince 图片来源:Prince 代码
What Is A Tool 什么是工具
A tool is essentially a Python function that we pass to the LLMs, enabling them to interact with the external world. You can write a tool that interfaces with your personal API, and the LLM can then call this tool, passing in the necessary arguments based on the user’s query. This allows for dynamic and powerful interactions between the LLM and external systems.
工具本质上是一个 Python 函数,我们将其传递给 LLMs ,使其能够与外部世界交互。你可以编写一个与个人 API 接口的工具,然后 LLM 可以调用这个工具,并根据用户的查询传递必要的参数。这样就可以在 LLM 和外部系统之间实现动态而强大的交互。
Why Tool Calling 为什么要调用工具
You might initially wonder why we need tool calling. After all, the LLM’s core role in a RAG system is synthesis. So, why does it need to call a function, also known as a tool?
你最初可能会问,为什么我们需要工具调用?毕竟,LLM 在 RAG 系统中的核心作用是合成。那么,它为什么需要调用一个函数,也就是所谓的工具呢?
Well, if you read the last article, remember how we determined the best route engine to execute when working with the Router Query Engine? The LLM, using a selector (LLMSingleSelector), was able to choose which router engine tool to use. This is just one example of why we need tool calling.
如果你读过上一篇文章,还记得我们在使用路由器查询引擎时如何确定执行的最佳路由引擎吗?LLM 通过使用选择器(LLMSingleSelector),可以选择要使用的路由器引擎工具。这只是我们需要工具调用的一个例子。
Imagine we’re building a booking system with an LLM or want to automatically write the output of a RAG pipeline into a file using an LLM-based system. We need to define a function that handles writing content to a file, then pass this function to the LLM. The LLM can then determine the necessary arguments to pass when calling this function. That function is a tool. Hopefully, these examples clarify why we might need function calling.
想象一下,我们正在使用 LLM 构建一个预订系统,或者想使用基于 LLM 的系统将 RAG 管道的输出自动写入文件。我们需要定义一个处理将内容写入文件的函数,然后将该函数传递给 LLM。然后,LLM 可以确定调用该函数时需要传递的必要参数。这个函数就是一个工具。希望这些示例能阐明我们为什么需要函数调用。
Setup And Initializations 设置和初始化
We’ll be using the environment we setup in the last article. The only difference it that I’ll create a new .ipynb that we’ll use for this article of tool calling.
我们将使用上一篇文章中设置的环境。唯一不同的是,我将创建一个新的 .ipynb ,用于本文的工具调用。
Image By Code With Prince 图片来源:Prince 代码
Sample Functions For Tools 工具函数示例
Let’s define a couple of functions we can later use as tools. In this case these could be any kind of function. Just make sure you have two very important things in your functions:
让我们定义几个我们以后可以用作工具的函数。在这种情况下,这些函数可以是任何类型的函数。只需确保在函数中包含两个非常重要的内容:
-
Type annotations: This will help the LLM know what kind of data or data type your function aka tool needs to be passed.
类型注释:这将帮助 LLM 了解你的函数(又称工具)需要传递哪种数据或数据类型。
-
Function do-strings: This will give a description of the tool aka function to the LLM so that it knows what the function or tool can be used for.
函数 do-strings:这将向 LLM 提供工具或函数的描述,以便它知道函数或工具可以用来做什么。
def add(x: int, y: int) -> int:
"""Add two numbers together."""
return x + y
# substraction function
def sub(x: int, y: int) -> int:
"""Substract two numbers."""
return x - y
# multiplication function
def mul(x: int, y: int) -> int:
"""Multiply two numbers."""
return x * y
# get user information
def get_user_info(name: str) -> str:
"""Get user information."""
data = {
"John Doe": {
"age": 30,
"location": "USA"
},
"Jane Doe": {
"age": 25,
"location": "UK"
}
}
return f'User name {name}, age is {data[name]["age"]} and location is {data[name]["location"]}'
Creating Tools From Python Functions 通过 Python 函数创建工具
Once we have these functions defined, we can then move ahead to turning this functions into tools that the LLM can invoke. To do this we can use the code block below:
定义好这些函数后,我们就可以将这些函数转化为 LLM 可以调用的工具。为此,我们可以使用下面的代码块:
from llama_index.core.tools import FunctionTool
addition_tool = FunctionTool.from_defaults(fn=add)
get_user_info_tool = FunctionTool.from_defaults(fn=get_user_info)
multiplication_tool = FunctionTool.from_defaults(fn=mul)
substraction_tool = FunctionTool.from_defaults(fn=sub)
tools = [addition_tool, get_user_info_tool, multiplication_tool, substraction_tool]
Testing Out The Tool Calling 测试工具调用
Now that we have managed to convert our Python functions into tools, let’s now test them by passing in a query that would require the use of one of the tools.
既然我们已经成功地将 Python 函数转换成了工具,现在让我们通过传递一个需要使用其中一个工具的查询来测试它们。
from llama_index.llms.openai import OpenAI
llm = OpenAI(model="gpt-3.5-turbo")
response = llm.predict_and_call(
tools,
"What is the product of 4 and 5",
verbose=True
)
print(str(response))
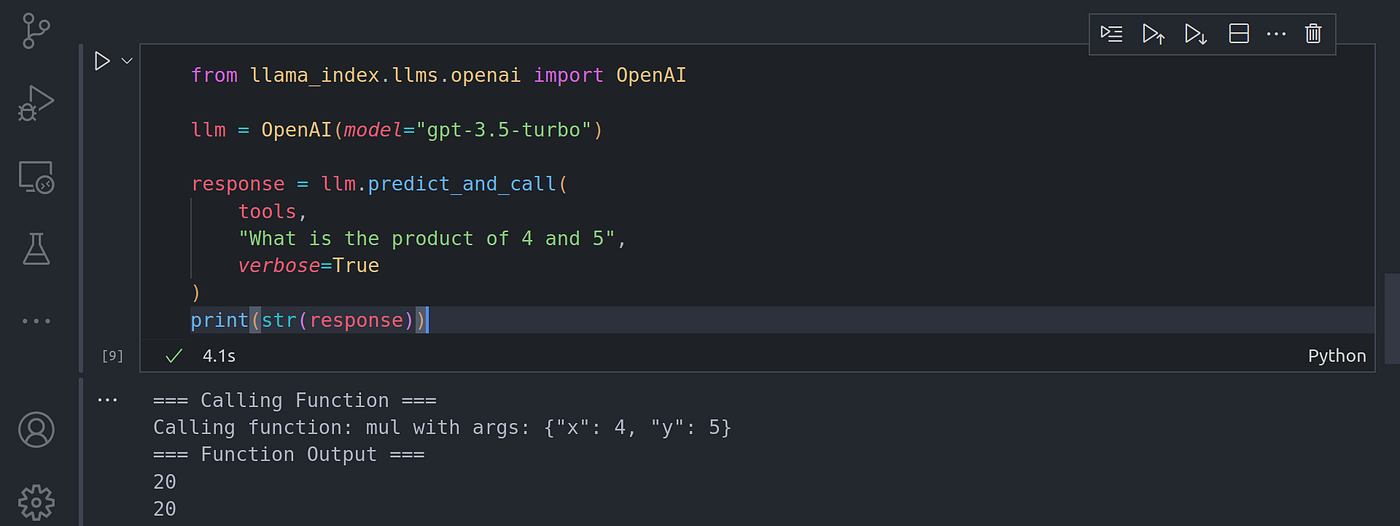
Image By Code With Prince 图片来源:Prince 代码
response = llm.predict_and_call(
tools,
"Give more the details of John Doe",
verbose=True
)
print(str(response))

Image By Code With Prince 图片来源:Prince 代码
Here we can see not only is the LLM able to know what function to call aka tools to call, but also what parameters to pass into those called functions and tools.
在这里,我们不仅可以看到 LLM 能够知道要调用什么函数,也能知道要调用什么工具,还能知道要向这些被调用的函数和工具传递什么参数。
Vector Search With Metadata 利用元数据进行矢量搜索
Since the LLM is able to know what tool to call and what function to pass in, we can utilize this to pass into the vector search tool metadata such as the page number of the document we want to search through.
既然 LLM 能够知道要调用什么工具和传递什么函数,我们就可以利用这一点向矢量搜索工具传递元数据,例如我们要搜索的文档的页码。
To create the search with metadata filtering capability, first we’ll need to build a simple vector search first, we’ll implement all we went over in the first article.
要创建具有元数据过滤功能的搜索,我们首先需要创建一个简单的矢量搜索,我们将实现第一篇文章中提到的所有功能。
from llama_index.core import SimpleDirectoryReader
# load lora_paper.pdf documents
documents = SimpleDirectoryReader(input_files=["./datasets/lora_paper.pdf"]).load_data()
from llama_index.core.node_parser import SentenceSplitter
# chunk_size of 1024 is a good default value
splitter = SentenceSplitter(chunk_size=1024)
# Create nodes from documents
nodes = splitter.get_nodes_from_documents(documents)
from llama_index.core import Settings
from llama_index.llms.openai import OpenAI
from llama_index.embeddings.openai import OpenAIEmbedding
# LLM model
Settings.llm = OpenAI(model="gpt-3.5-turbo")
# embedding model
Settings.embed_model = OpenAIEmbedding(model="text-embedding-ada-002")
from llama_index.core import VectorStoreIndex
# vector store index
vector_index = VectorStoreIndex(nodes)
Adding metadata filtering capability: 添加元数据过滤功能:
from llama_index.core.vector_stores import MetadataFilters
# Create vector search query engine
query_engine = vector_index.as_query_engine(
similarity_top_k=2,
filters=MetadataFilters.from_dicts(
[
{"key": "page_label", "value": "2"}
]
)
)
response = query_engine.query(
"Tell me about the Problem statement as explained",
)
print(str(response))

Image By Code With Prince 图片来源:Prince 代码
In the code above, we are limiting the search to page 2 only, where they talked about the problem statement in the research paper. We can confirm that the search was only done on page 2 using:
在上面的代码中,我们将搜索范围限制在第 2 页,即研究论文中谈到问题陈述的地方。我们可以使用以下方法确认搜索只在第 2 页进行:
for n in response.source_nodes:
print(n.metadata)
print("=============Text=============")
print(n.get_text())
print("=============Text=============")
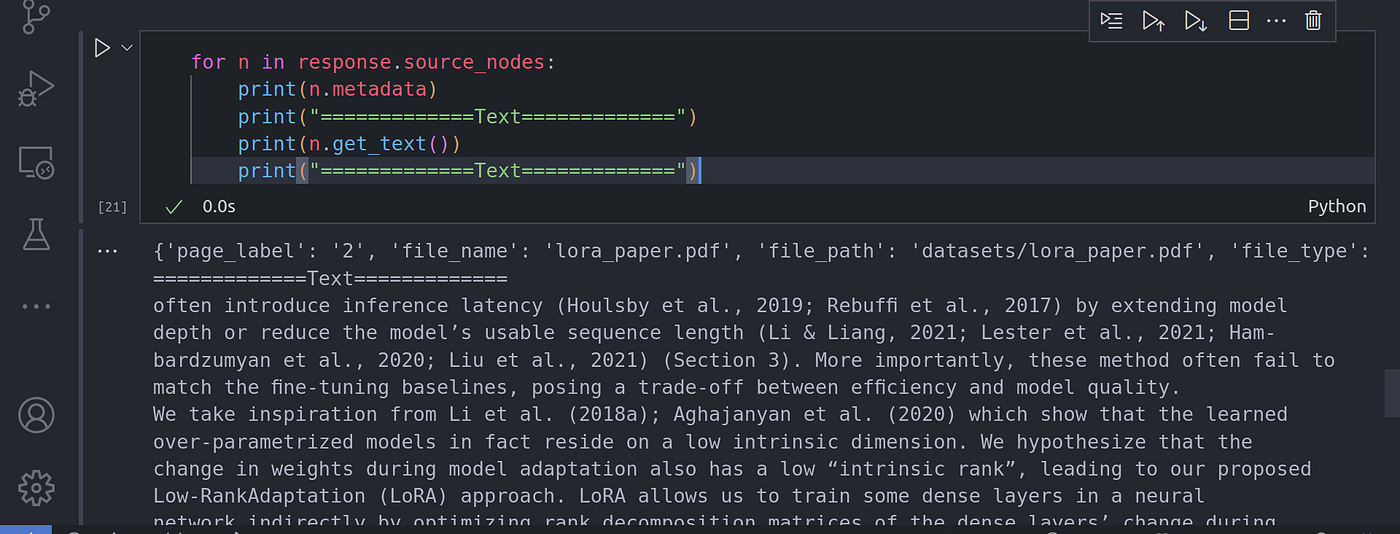
image By Code With Prince 图像 代码与王子
From the image of the code execution above, you can see that the search of the nodes is limited to page number two only. You can pass in other metadata as well.
从上面的代码执行图像中可以看到,节点搜索仅限于第二页。您还可以输入其他元数据。
Auto-Retrieval Tool 自动检索工具
Now that we are able to retrieve content by specifying other metadata. One thing you can notice is that we had to manually specify the metadata filter. In most cases, this is not ideal. Can we get the LLM specify in the filter itself based on what user query was passed. Example:
现在,我们可以通过指定其他元数据来检索内容。有一点你可以注意到,我们必须手动指定元数据过滤器。在大多数情况下,这并不理想。我们能否根据用户查询的内容,在过滤器中指定 LLM 呢?例如
*“What was mentioned about the problem statement in page 2?” “第 2 页中提到的问题陈述是什么?*
From this query, the LLM should be able to pass in the page number metadata filter as 2. Let’s implement this:
从这个查询中,LLM 应该能在页码元数据过滤器中传递为 2。让我们来实现这一点:
First let’s implement the vector query search: 首先让我们实现矢量查询搜索:
from typing import List
from llama_index.core.vector_stores import FilterCondition
def vector_search_query(
query: str,
page_numbers: List[str]
) -> str:
"""Conduct a vector search across an index using the following parameters:
query (str): This is the text string you want to embed and search for within the index.
page_numbers (List[str]): This parameter allows you to limit the search to
specific pages. If left empty, the search will encompass all pages in the index.
If page numbers are specified, the search will be filtered to only include those pages.
"""
metadata_dicts = [
{"key": "page_label", "value": p} for p in page_numbers
]
query_engine = vector_index.as_query_engine(
similarity_top_k=2,
filters=MetadataFilters.from_dicts(
metadata_dicts,
condition=FilterCondition.OR
)
)
response = query_engine.query(query)
return response
vector_query_tool = FunctionTool.from_defaults(
name="vector_search_tool",
fn=vector_search_query
)
response = llm.predict_and_call(
[vector_query_tool],
"What was mentioned about the problem statement in page 2?",
verbose=True
)
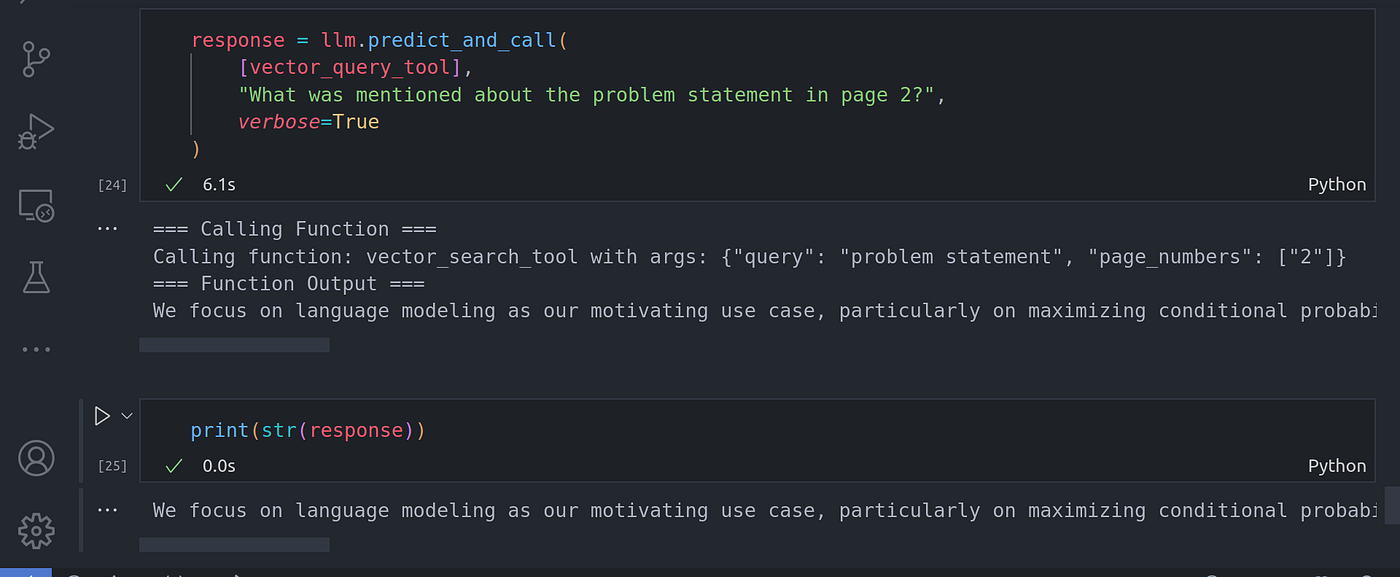
Image By Code With Prince 图片来源:Prince 代码
Now you can see the function call is done automatically passing in the righ metadata as page 2. The LLM was able to infer the page number metadata filter. There are other metadata filters we can use such as footer metadata filters.
现在你可以看到函数调用是自动完成的,将右侧元数据作为第 2 页传入。LLM 能够推断出页码元数据过滤器。我们还可以使用其他元数据过滤器,例如页脚元数据过滤器。
We can confirm the data was retrieved from page 2 using the following:
我们可以通过以下方式确认数据是从第 2 页获取的:
for n in response.source_nodes:
print(n.metadata)
print("=============Text=============")
print(n.get_text())
print("=============Text=============")
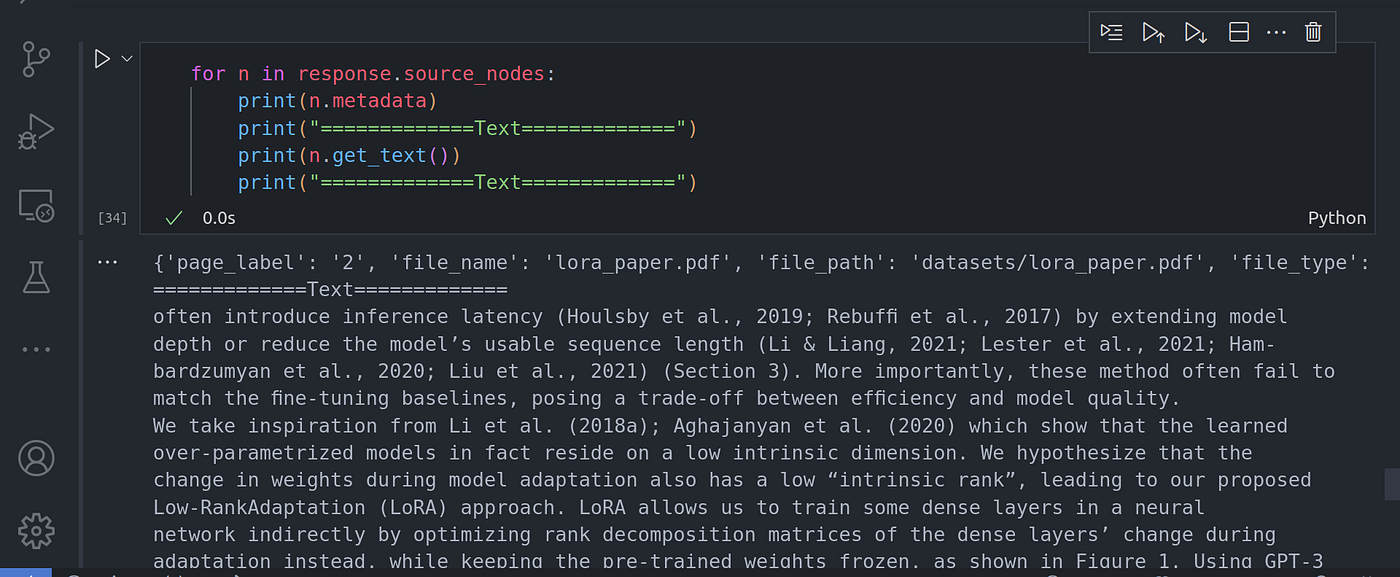
Image By Code With Prince 图片来源:Prince 代码
Now, let’s incorporate the summary tool to make sure the router is able to pick the right query engine tool to use.
现在,让我们结合摘要工具,确保路由器能够选择正确的查询引擎工具。
from llama_index.core import SummaryIndex
from llama_index.core.tools import QueryEngineTool
summary_index = SummaryIndex(nodes)
summary_query_engine = summary_index.as_query_engine(
response_mode="tree_summarize",
use_async=True,
)
summary_tool = QueryEngineTool.from_defaults(
name="summary_tool",
query_engine=summary_query_engine,
description=(
"Useful for summarization questions related to the Lora paper."
),
)
response = llm.predict_and_call(
[vector_search_query_tool, summary_tool],
"What was mentioned about the problem statement in page 2?",
verbose=True
)
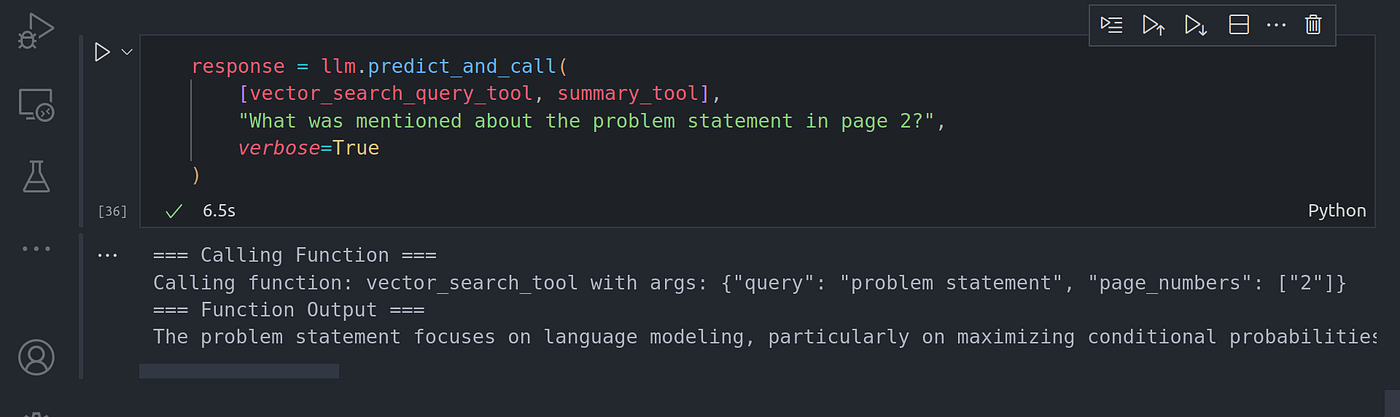
Image By Code With Prince 图片来源:Prince 代码

Image By Code With Prince 图片来源:Prince 代码
response = llm.predict_and_call(
[vector_search_query_tool, summary_tool],
"Give me a summary of the paper.",
verbose=True
)
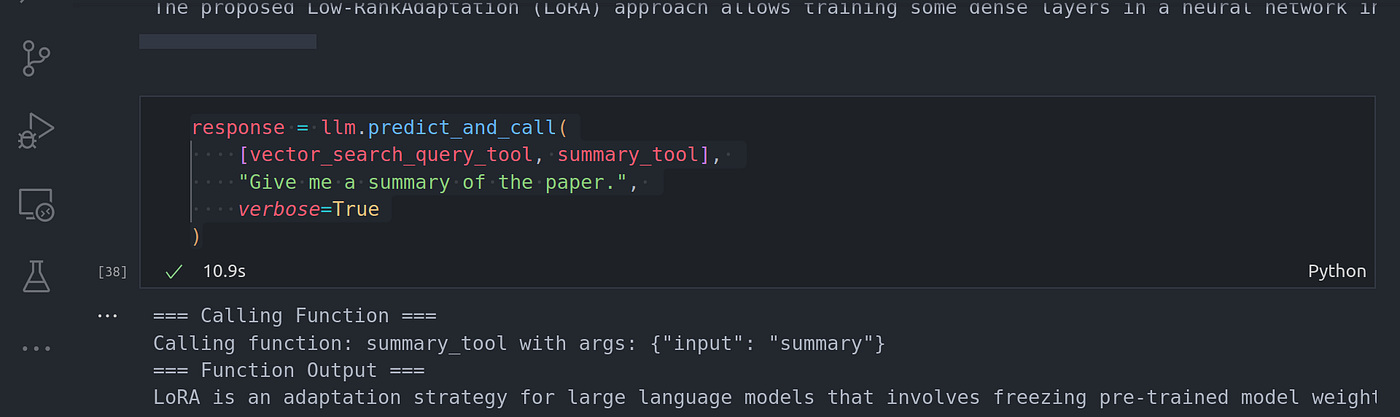
Image By Code With Prince 图片来源:Prince 代码
for n in response.source_nodes:
print(n.metadata)
print("=============Text=============")
print(n.get_text()[:10])
print("=============Text=============")
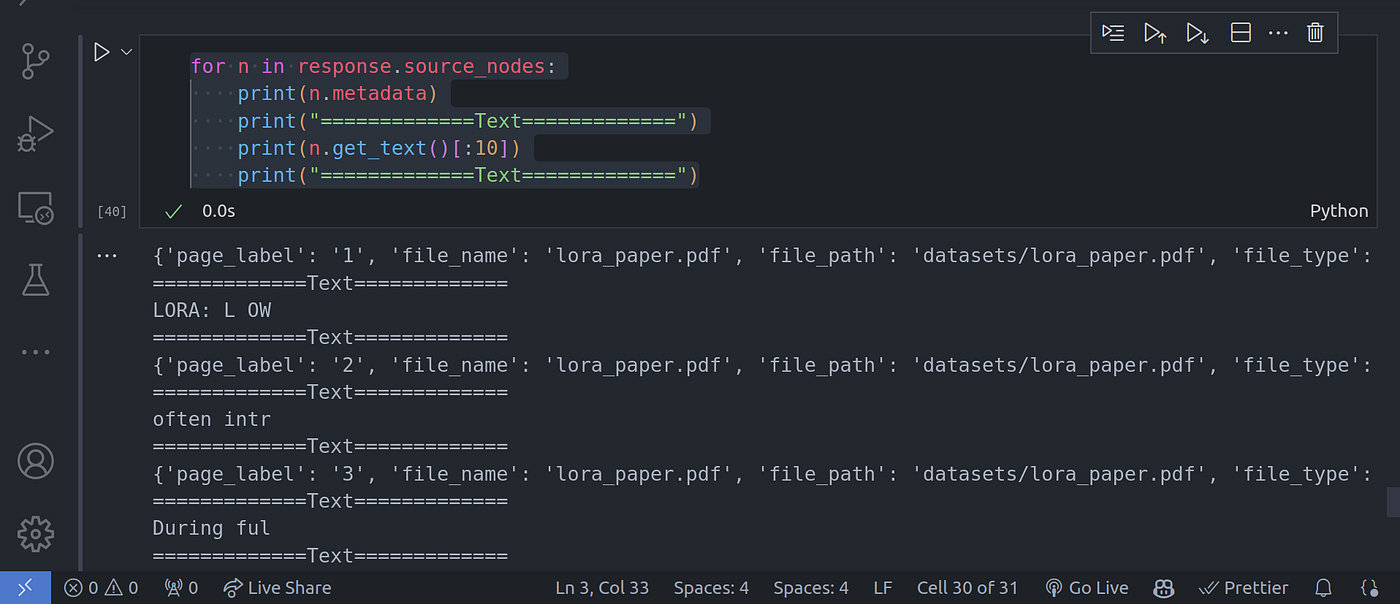
Image By Code With Prince 图片来源:Prince 代码
Conclusion 结论
Congratulations for making it this far. We have taken a deep dive into tool calling. So far everything we have done from the first article has been revolving around single shot prompting where everything is done in a single loop.
恭喜你走到了这一步。我们已经深入了解了工具调用。从第一篇文章到目前为止,我们所做的一切都围绕着单次提示,即在一个循环中完成所有操作。
This has some limitations, let’s address this in the next article when we dive into reasoning loop with multi-step reasoning.
这有一定的局限性,让我们在下一篇文章中讨论这个问题,届时我们将深入探讨多步推理的推理循环。
Other platforms where you can reach out to me: 其他可以联系我的平台:
*Happy coding! And see you next time, the world keeps spinning. 编码快乐!下次再见,世界在继续转动。*